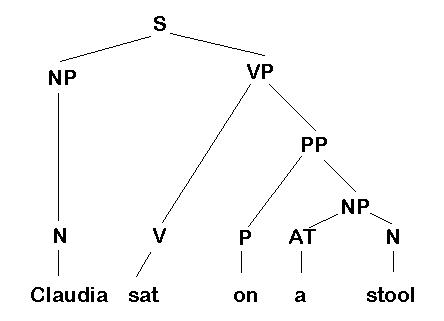
(S=sentence, NP=noun phrase, VP=verb phrase, PP=prepositional phrase, N=noun, V=verb, AT=article, P=preposition.)
Such visual diagrams are rarely encountered in corpus annotation - more often the identical information is represented using sets of labelled brackets. Thus, for example, the above parsed sentence might appear in a treebank in a form something like this:
[S[NP Claudia_NP1 NP][VP sat_VVD [PP on_II [NP a_AT1 stool_NN1 NP] PP] VP] S]
Morphosyntactic information is attached to the words by underscore characters ( _ ) in the form of part-of-speech tags, whereas the constituents are indicated by opening and closing square brackets annotated at the beginning and end with the phrase type e.g. [S ...... S]
Sometimes these bracket-based annotations are displayed with indentations so that they resemble the properties of a tree diagram (a system used by the Penn Treebank project). For instance:
[S
[NP Claudia NP]
[VP sat
[PP on
[NP a stool NP]
PP]
VP]
S]
In depth: You might want to read about full parsing, skeleton parsing, and constraint grammar by following this link.
Because automatic parsing (via computer programs) has a lower success rate than part-of-speech annotation, it is often either post-edited by human analysts or carried out by hand (although possibly with the help of parsing software). The disadvantage of manual parsing, however, is inconsistency, especially where more than one person is parsing or editing the corpus, which can often be the case on large projects. The solution - more detailed guidelines, but even then there can occur ambiguities where more than one interpretation is possible.