 |
 |
| Corpus Linguistics Home |
| Page index |
|
 WordSmith WordSmith |
| Basic WordSmith |
| Using Concord |
 Frequency Lists and Keywords Frequency Lists and Keywords |
| Part-of-speech Tags |
| BNCweb |
| DIY Corpora |
Current page |
Page Two |
Page Three |
Page Four |
|||
Making WordlistsA. Making a wordlist from a single corpus textOur example file is a newsletter from Queen's Park Baptist Church in Glasgow. Before you create the wordlist, you might like to think about what words it's likely to contain... Now follow these steps to make the wordlist:
You should now have something that looks like this: 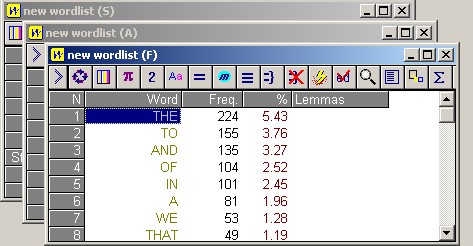 There are three different wordlist windows. Look at each window one by one. To move between them click on the word Window at the top and choose 1, 2 or 3. Wordlist (F): frequency list, where words are listed with the most frequent coming first, descending to the least frequent. (Scroll down and see.) Wordlist (A): alphabetical list. The same list as above but with words in alphabetical order. Wordlist (S): statistics file
Look at the screenshot below. Each word in green is a type. The Freq. column gives the number of tokens. 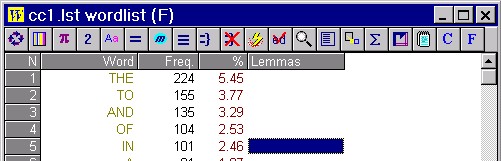
B. Making a wordlist from a set of corpus textsFile bapt-a.txt is one of 9 similar Baptist texts. To get a bigger picture of the vocabulary of the newsletter, it will be useful to create one wordlist for all 9 texts. Make a wordlist of the entire Baptist church corpus (file "bapt-a" through to "bapt-i") and save it as bapt.lst in the same location as before. We will use this file in the next exercise.
|
||||||


