Sample corpus files
The links below lead to HTML versions of two corpus files, Mercurius Politicus Issue 188 and The Perfect Diurnall... Issue 215. You can view a version with or without regularised spellings. You can also view graphical scans of the original documents.
Lower down this page, you can see the results of applying the TESAS software to this pair of texts.
|
The Perfect
Diurnall, Issue 215
(pub. 16th Jan. 1654) |
Mercurius
Politicus, Issue 188
(pub. 19th Jan. 1654) |
Sample analysis for the text re-use project
First, the two texts are loaded into the Corpus Toolkit developed by Scott Piao. The TESAS algorithm is embedded in this toolkit.
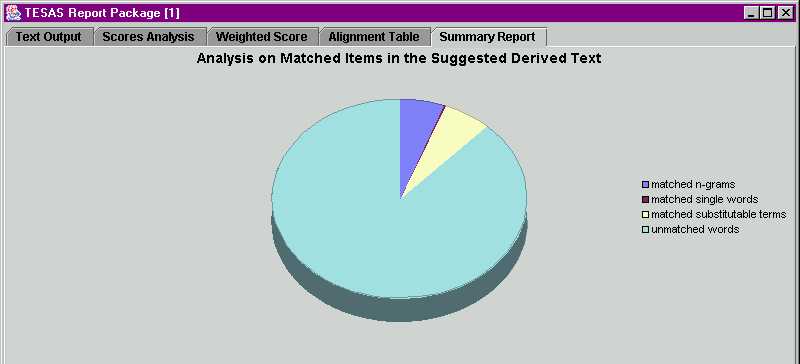
The algorithm scans for matching word strings and maps related sentences, on the basis of which the similarity between the texts is estimated. The results are displayed in a number of ways. Firstly, we can find the percentage of the texts that appears to be identical (i.e. deriving one from the other, or both from the same source).
A more sophisticated analysis shows that the points of similarity are bunched together at one particular point in the text. This suggests that these two newsbooks have a single story in common - a degree of similarity which is reflected in the fairly low percentage of similarity in the screenshot above.
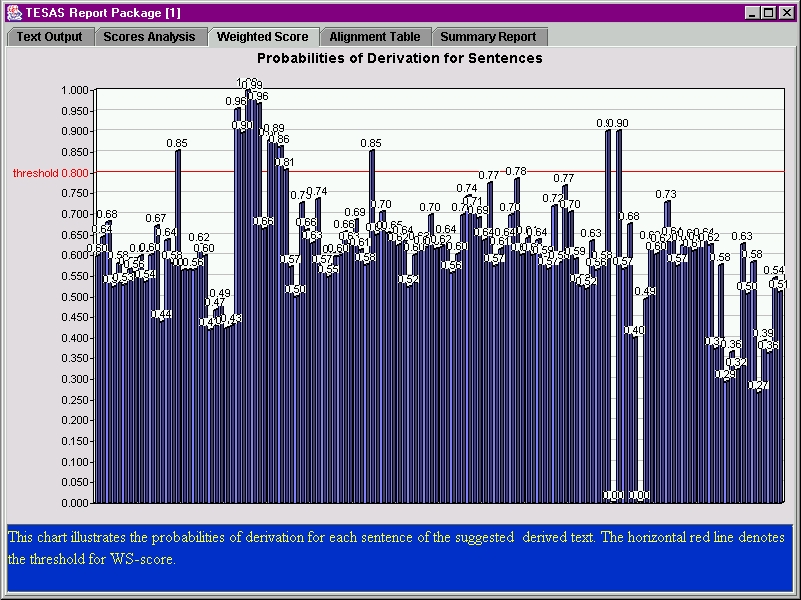
Note that the threshold value shown in the chart above, 0.8, was found by experiment to filter out the noise of non-significant intertextual similarity while not excluding the genuine similarities in which we are interested.
Examination of the texts in an aligned layout suggests that they do indeed have a single story in common - shared words are highlighted in red, shared phrases in green. Other stories have not been correlated to one another.
