No Time to Read My Blog? Try Spritzing
1st April 2016
This week I came across a very interesting idea developed by a company called Spritz, which is
looking at ways of helping people read more efficiently and understand more. As I have spent a great deal of time recently reading
papers, at quite a slow speed, this grabbed my attention. After reading a little bit about it, it occurred to me that this might be
a classification problem from Machine Learning, something that a fellow STOR-I student,
Kathryn Turnbull, spoke about in her presentations last week. So, in this blog
I would like to briefly discuss what “spritzing” is, motivate it, and then talk about classification. (I’m afraid the first bit will
be rather unrelated to statistics, but I will get to that bit at some point.)

Words have a focus point called the Optimal Recognition Position (ORP) that, as the name suggests, is the point at which the eyes
focus to help the brain optimally recognise and understand the word. Once the ORP is found, the word as a whole can be recognised by
its shape. When reading, the eyes scan over the word to find where the ORP is for that word. This involves moving the eyes over the
word, possibly multiple times if the word is unfamiliar, before the ORP is found. Punctuation is a trigger for the brain to put all
of the words together and make sense of the whole thing. It is this eye movement that causes delays in understanding and slows down
reading.
However, what if the ORPs were all in the same place? And, in addition they were printed so that they were the obvious place to focus?
Then the eye would not have to search for ORPs and in theory should speed up the process of understanding what you are reading. This
is the aim of spritzing. The words of the text being read are displayed momentarily, aligned using the positioning of ORP, which is
highlighted red. Now, providing that the words are displayed for an appropriate length of time for the brain to understand, the text
should be quicker to get through. The idea is shown in the picture on the right of this page.
Spritzing can be applied to all sorts of texts, but the main thing is an application that can be added to an internet browser that
can translate all text on the internet into Spritz form.
Words have a focus point called the Optimal Recognition Position (ORP) that, as the name suggests, is the point at which the eyes
focus to help the brain optimally recognise and understand the word. Once the ORP is found, the word as a whole can be recognised by
its shape. When reading, the eyes scan over the word to find where the ORP is for that word. This involves moving the eyes over the
word, possibly multiple times if the word is unfamiliar, before the ORP is found. Punctuation is a trigger for the brain to put all
of the words together and make sense of the whole thing. It is this eye movement that causes delays in understanding and slows down
reading.
However, what if the ORPs were all in the same place? And, in addition they were printed so that they were the obvious place to focus?
Then the eye would not have to search for ORPs and in theory should speed up the process of understanding what you are reading. This
is the aim of spritzing. The words of the text being read are displayed momentarily, aligned using the positioning of ORP, which is
highlighted red. Now, providing that the words are displayed for an appropriate length of time for the brain to understand, the text
should be quicker to get through. The idea is shown in the picture on the right of this page.
Spritzing can be applied to all sorts of texts, but the main thing is an application that can be added to an internet browser that
can translate all text on the internet into Spritz form.
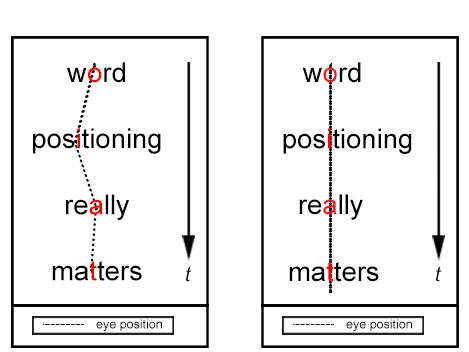
How normal reading and spritzing work (on left and right). Images 1 and 2 from reference [2].
The question I was left with was, how would Spritz deal with a word that it hasn’t come across before? There are a lot of technical
words in the English language that would not appear in just any circumstance. Some of the words in the papers I read online are not everyday words. And even if there was a Spritz library containing all
the words in the English language, surely they didn’t employ someone to find the ORP for every word manually? I then thought that this
could be an application of machine learning and classification.
Classification in Machine Learning is the topic of trying to get a computer able to distinguish between different groups of objects.
One branch of this is “supervised learning” in which there are a set of objects whose groups are known and the computer has to put
new objects into the appropriate group. One approach is to try to find the “boundaries” of these groups that maximise the difference
between them. The easiest way to do this is to associate each object with a vector in $\mathbb{R}^n$, generally using measurements
based on the object, and finding linear functions, such as lines or planes, to separate them. This can be generalised curved
boundaries by adding extra dimensions.
There are two things to decide for every word that the application reads:
- Where is the ORP for this word?
- How long does this word to be displayed, in comparison to other words?
For the first, the general rule is that as words get longer, the ORP shifts from the centre towards the left hand side. This could be
done relatively straightforwardly, but it does not apply to all words. So the machine needs some way of comparing a new word to others,
with length being the most important part.
The more difficult problem comes from how long to display the word. Intuitively, the longer the word, the longer the display time.
However, short words like “bid” and “did” are quite similar to look at. This means that they take longer to distinguish from each other
than longer words that have a more distinctive shape. If words are similar to other words and long, they require longer still. This is
clearly a complex matter, and so clever classification models must be used. Somehow, shapes of words must be placed into mathematical
vectors that can be grouped. It must also be done quickly, as a reader doesn’t want to hang around for half an hour whilst the text is
translated into a form to be read quickly.
I hope this application has been interesting for you. I am sorry it wasn’t heavy on the maths side, but I thought it an interesting idea
and showed an application of Machine Learning.
References
[1] Spritz: the science
[2] Why Spritz Works: It’s All About the Alignment of Words