STOR-i Conference 2020

Last week I got to start off the new year at Lancaster by attending the annual STOR-i conference. I was able to sit through a day and a half of talks from academics coming from around the UK as well as Europe and America. My first blog will be about my favourite talk from this year’s conference, ‘Multi-armed bandit problems with history dependent rewards’ by Ciara Pike-Burke a STOR-i Alumni.

What is a Multi-armed bandit?
Consider you have a row of \(n\) slot machines in front of you each with a fixed rewards structure. You are given £\(H\) to play the machines and each cost £\(1\) to play, with your objective to be take home as large winnings as possible! How to tackle this problem is not as simple as it might first look and there have been many different approaches to come up with a strategy to optimize, i.e. the decision process.
What is the point?
This may sound like a rather abstract problem but in fact there are important applications we can use bandits for, and one of the most widely used is in advertising. Say now instead of being sat at a row of slot machines you are an internet advertiser considering which advert to display to a customer. The rewards in this case could be how many customers click, or how much they go and spend on the advertised link.
What are history dependent rewards?
This approach to internet advertising does not apply to all kinds of products that someone might wish to advertise. The example given was sofas, I may go and buy a sofa off an advert and thus make it appear I am interested in sofas. But now the traditional policies for bandits would make it more likely that I see the same advert next time I am displayed one. The point is now I have a sofa and do not want to see this advert in the immediate future. Hence, this gives the importance of having history dependent rewards.
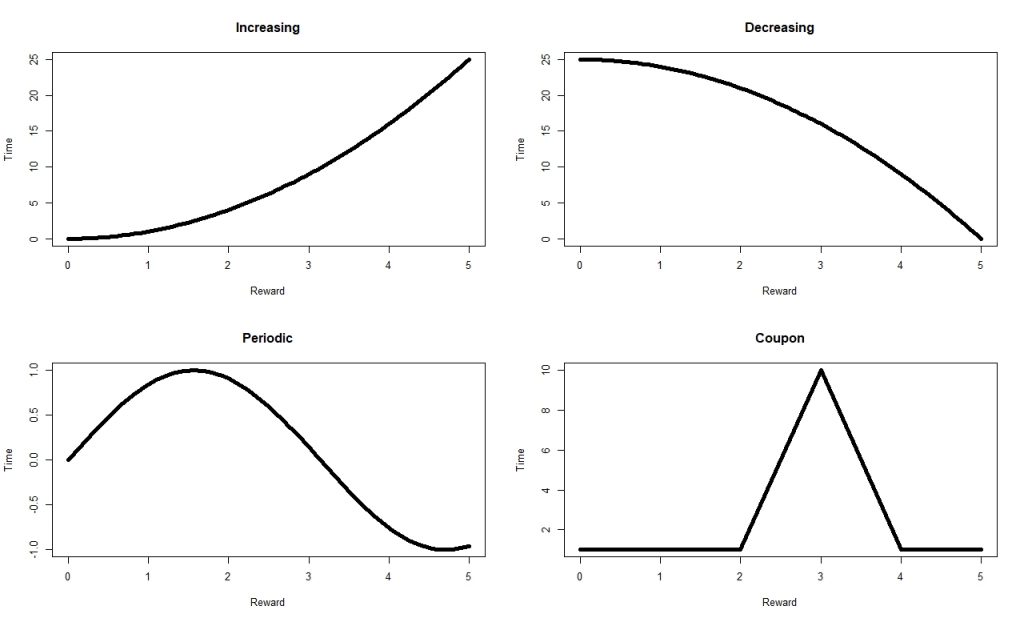
This is an example of a periodic reward as the desire for a sofa increases and decreases over time. There are other kinds of history dependent rewards, the simplest being strictly increasing or decreasing rewards for example representing loyalty to a company. A more complex reward structure could be coupon rewards. Think of when you go to your favorite café and get stamps on your loyalty card and after so many visits you get a free coffee. This is essentially the set up but now we do not know the number of stamps we need to acquire or the prize we get at the end.
How can we solve this?
We can try to predict what the rewards will look like from all the arms in some small future time interval and use these to try to plan our next best move. For example, if a customer has just clicked on an advert for a sofa, I might want to wait a while until the same advert is shown and instead give adverts for coffee tables instead. In the presentation we were told about how you could use something called a Gaussian process to predict the reward function. Given our prediction of these we can then optimize our next d steps in order to achieve maximum profit. Obviously if we could look at every decision we would ever make then this would be optimal, but in practice a computer cannot do this thus we have to decide on a small fixed time period to consider.
References:
Ciara Pike-Burke, Steffen Grünewälder (2019) Recovering Bandits