Following our last post, Extracting and Creating Data from the Geographic Relations of New Spain, in which I mentioned the problems we face in automatized identification of place-names, I thought it would be worthwhile to take a look at the toponyms we are working with, and why using computational approaches will allow us to further our understanding of the Relaciones Geográficas.
One of our first, and ongoing, challenges with this project is the identification of thousands of place-names across Mesoamerica. The source materials for the gazetteer we are currently compiling include:
Rene Acuña’s Relaciones Geográficas del Siglo XVI
Mercedes de la Garza’s Relaciones Histórico-geográficas de la Gobernación de Yucatán
Alejandra Moreno Toscano’s Geografia económica de Mexico
Francisco del Paso y Troncoso’s Suma de visitas de pueblos de Nueva España
Peter Gerhard’s A Guide to the Historical Geography of New Spain and The Southeast Frontier of New Spain
Our first task was cleaning and converting each of these sources into a computer-readable format, allowing us to extract data more easily. OCR was (sometimes) our friend for this part of the process. We were then able to extract all the place-names listed in the indexes of these works (correcting OCR mistakes along the way), leaving us with a list of almost 14,500 toponyms. Of course, many of these are duplicates or alternate spellings of the same place. We are currently disambiguating these place-names to ensure we are referring to the correct location. (I described this process in our Historical GIS post if you’d like a little more detail about this.)
The wordcloud below was created from the full list of toponyms listed in Rene Acuña’s editions of the Relaciones Geográficas, excluding alternate spellings for the same place. If I had included the alternate spellings, the list would have been over 6,200 names. As it was, I inputted a list of around 4,900 toponyms.

The influence of the Spanish language is clear, though not surprising, with names of saints featuring prominently alongside common descriptors such as Río, Valle and Laguna. However, indigenous toponyms remain prevalent, with frequent mentions of specific locations such as Acámbaro, Tlaxcala and Ixtlahuacan. Yucu, a Mixtec word meaning ‘hill’, appears 33 times, no less frequently than Valle. The occurrence of Yucu in this source material was also exclusively within the region of Antequera (currently Oaxaca), explained by the region being home to the convergence of numerous mountain chains, known as the Complejo Oaxaqueño (Oaxaca Complex).
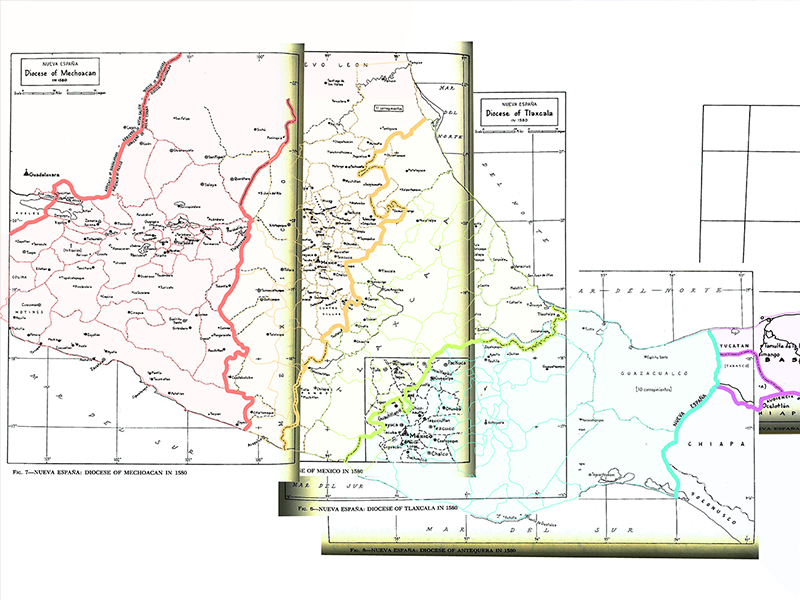
Disambiguating the thousands of place-names which are mentioned in the Relaciones Geográficas will allow us to effectively interact with the source material using computational methods. Using techniques such as Collocation Analysis in conjunction with our gazetteer will open up opportunities for analysing the text in innovative ways, such as identifying associations between locations, entities, topics etc. For example, it should be possible to search for Tlacotepec and determine whether this place has any relationship to another place, person, or concept. Furthermore, it will be possible to search for the specific Tlacotepec which you may be interested in, and any associated alternate names/spellings for that particular place. As the map below demonstrates, place-names are often repeated across, and within, regions. This is why disambiguating our corpus is so important!

At present, we have a total of 3,650 fully disambiguated place names – meaning that we have definite coordinates assigned to these names. You can see a sample of some of these locations on the Corpus and Datasets tab of our website.
We have a fair few more toponyms which are partially located (i.e. we have identified the region in which they lie), and thousands more awaiting disambiguation. We’re approaching the halfway point…just over the next yucu!