So Reinforcement Learning Intellegence can now beat us as a game that we humans have been playing for a good few millennium. So what? And more importantly, where is Reinforcement Learning heading now?
Well, something to point out is that it’s not just Go… or Chess or Backgammon. It’s the better part of everything. In 2019, OpenAI Five became the first AI system to defeat the world champions at an esports game. The game in question was Dota 2, a free-to-play Real Time Strategy (RTS) / Multiplay Online Battle Arena (MOBA) game that regularly sees hundreds of thousands active players at any one given time. The game is actively played by full time professionals, and the prizepool for the 2020 international championship exceeded $40 million. Forty Million Dollars.
Dota 2 International Announcement
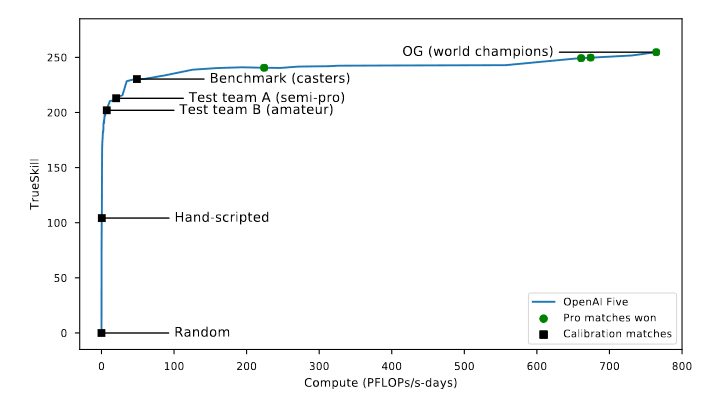
Such an open enviroment has serious challenges for AI systems, such as long time horizons, imperfect information, and both complex, continuous state-action spaces (https://arxiv.org/abs/1912.06680). OpenAI Five would go on to defeate the at time world champion team, demonstrates that self-play reinforcement learning can completely surpass human ability in an extremely complex enviroment. This was done by applying existing reinforcement learning techniques, where the enviroment was scaled to learn from batches of approximately 2 million frames every 2 seconds. This process took 10 months.
OpenAI Five Progress in Skill vs Computation (Dota 2 with Large Scale Deep Reinforcement Learning, Berner, Brockman, Chan et al., 2019, https://arxiv.org/abs/1912.06680)
So Reinforcement Learning, given enough time, is incredibly powerful when solving one specific task. It’s not an unreasonable assumption that if self-play can get Reinforcement Learning to surpass humans at Dota 2, then it should be possible for nearly any competitive game. But extending it, from one AI learning one game to one AI learning multiple different and unique rulesets is a different problem entirely. This leads us into the realm of Meta-Learning.
Meta Learning is the idea of teaching an AI to learn how to learn, with the goal of many Artificial Intelligence developers to eventually reach some form of Artificial General Intelligence, Meta Reinforcement Learning is commonly seen as the next step. There also exists the posibility that learning how to learn can be leveraged to speed up existing learning in deepRL.
The team at OpenAI have been working on MuZero, which rather than trying to model the entire environment the agent might encounter, MuZero just models aspects that are important to the agent’s decision-making process. As the OpenAI blog (https://deepmind.com/blog/article/muzero-mastering-go-chess-shogi-and-atari-without-rules) clarifies, “knowing an umbrella will keep you dry is more useful to know than modelling the pattern of raindrops in the air”.
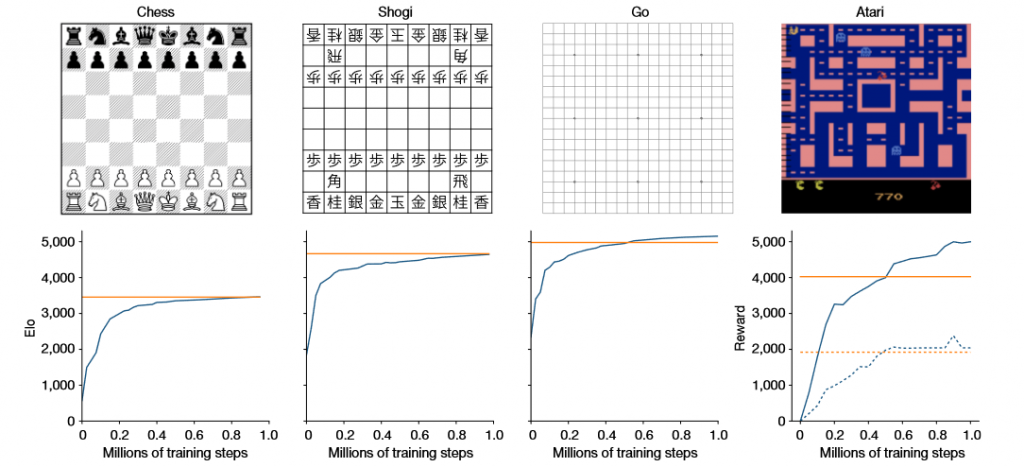
MuZero only looks to model three elements from the enviroment (see the example way back with MDPs) that are the only three strictly necessary components. The value of a current position, the Policy the agent is following and the reward it just recieved. That’s it. In only focusing on the strictly necessary, MuZero is already able to learn and compete with other specifically designed Reinforcement Learning AI at Atari games that Mu has never seen before, does not know the rules of, has no human input has no access to any prior/external knowledge. Not only this, but a variant called MuZero Reanalyze can use the learned model 90% of the time to re-plan what should have been done in past episodes.
Performance of MuZero in Chess, Shogi, Go and Atari over time (Schrittwieser, J., Antonoglou, I., Hubert, T. et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 588, 604–609 (2020). https://doi.org/10.1038/s41586-020-03051-4)
Is MuZero going to take over the world Terminator style? Probably not… But the potential applications to, for example, healthcare, are genuinely exciting. All the best,
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.